AI 时代的编程语言,这次是来自中国的底层创新
AI 时代的编程语言,这次是来自中国的底层创新近期知名高性能开源项目 Bun 将核心代码大规模重写为 Rust ,则给出了一个更具体的产业信号:当 AI 降低迁移成本之后,软件基础设施正在重新向更强约束、更高性能、更易被机器检查的语言迁移。但 Rust 毕竟诞生于生成式 AI 爆发之前;其核心设计目标是安全的底层编程,而非 Agent 之间的高效协作。
来自主题: AI资讯
9537 点击 2026-07-09 17:04
 搜索
搜索
近期知名高性能开源项目 Bun 将核心代码大规模重写为 Rust ,则给出了一个更具体的产业信号:当 AI 降低迁移成本之后,软件基础设施正在重新向更强约束、更高性能、更易被机器检查的语言迁移。但 Rust 毕竟诞生于生成式 AI 爆发之前;其核心设计目标是安全的底层编程,而非 Agent 之间的高效协作。
开发 AI Agent 最崩溃的不是写代码,而是调 Bug——你根本不知道它中间经历了什么。 你精心设计了一个 Agent 工作流:接收需求 → 拆解任务 → 调用工具 → 返回结果。测试通过,信心满满地上线。

这个问题,在 AI 行业有一个专业的说法:无状态(Stateless)。而解决这个问题,正是 EverMind 过去一直在做的事情。今天,这个探索走到了一个新的节点:基于自研记忆系统 EverOS 的自进化Harness——Raven Agent 正式发布。

现在的 AI Agent 动辄需要处理超长上下文,既要看系统提示词、工具说明,又要翻阅历史对话和检索文档。为了省钱、省算力并降低延迟,很多开发者会给系统加上 “提示词压缩”(Prompt Compression)模块,把冗长的上下文浓缩后再喂给大模型。

刚刚,DeepSeek 在官方 API 文档里给出了一个 thinking mode 和 tool call 结合使用的样例。表面上看,这只是一个常规的工具调用演示:用户提出问题,模型判断需要调用工具,工具返回结果后,模型再继续生成答案。
Greg Isenberg 最近在他自己的播客 The Startup Ideas Podcast 里讲的一个判断,他说了一句很直白的话,building agents is the new SaaS,做 agent 就是新时代的 SaaS。
两个月的时间,混元 3 正式版上线。结合了用户对预览版的反馈以及对模型稳定性和可用性的提升,Hy3 在 Agent 和 Coding 能力上有了实质的提升。我们做了多个前端网页的生成测试,大多数都包含复杂的 3D 网页模拟、严格的游戏逻辑,以及需要调用不同的框架和库文件,Hy3 交付的内容要比预览版好上一个等级。
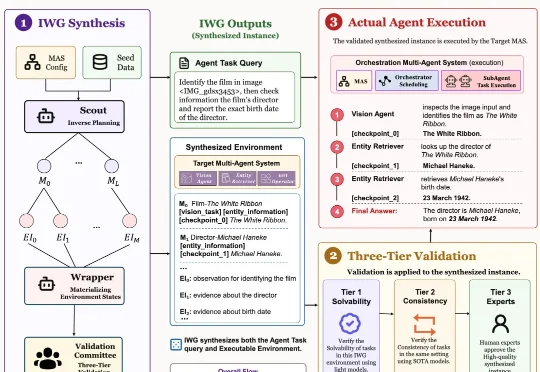
来自南京大学 NLP 实验室的 ICML 2026 论文 Recognize Your Orchestrator: An Entropy Dynamics Perspective for LLM Multi-Agent Systems 指出:在当前主流的 Orchestrator-Executor 多智能体架构中,系统失败往往并不首先来自某个执行器不会干活,
据DeepSeek官方API文档及GitHub仓库信息,一款名为Deep Code的第三方开源AI编程助手近日被收录进DeepSeek Agent工具。该工具面向DeepSeek-V4系列模型做了适配,支持深度思考、推理强度控制、Agent Skills以及MCP集成。截至发稿,Deep Code GitHub仓库显示,该工具收获超1500星、127 fork。

今天想和大家分享一种业务建模方法:Agent Ontology,Agent 本体论 Ontology 是我在研究 Palantir 时不断出现的一个词,仔细研究后觉得很有必要单独拿出来,和大家分享。 首先,Ontology 不是单纯的方法论,也不是单独一个工具。